Word2vec è un modello (evoluzione Doc2vec)
Vector space models (VSMs) represent (embed) words in a continuous vector space where semantically similar words are mapped to nearby points ('are embedded nearby each other')
Word2vec is a particularly computationally-efficient predictive model for learning word embeddings from raw text. It comes in two flavors, the Continuous Bag-of-Words model (CBOW) and the Skip-Gram model (Section 3.1 and 3.2 in Mikolov et al.)
Skip Gram Model
Bag-Of-Words Model
Il modello è semplice perchè usa un trucco del auto-encoder l'output layer fa deve ritornare la stessa cosa dell'input (apprendimento supervisionato anche se non si hanno le label) poi si rimuove il livello di output e si ottengono i pesi
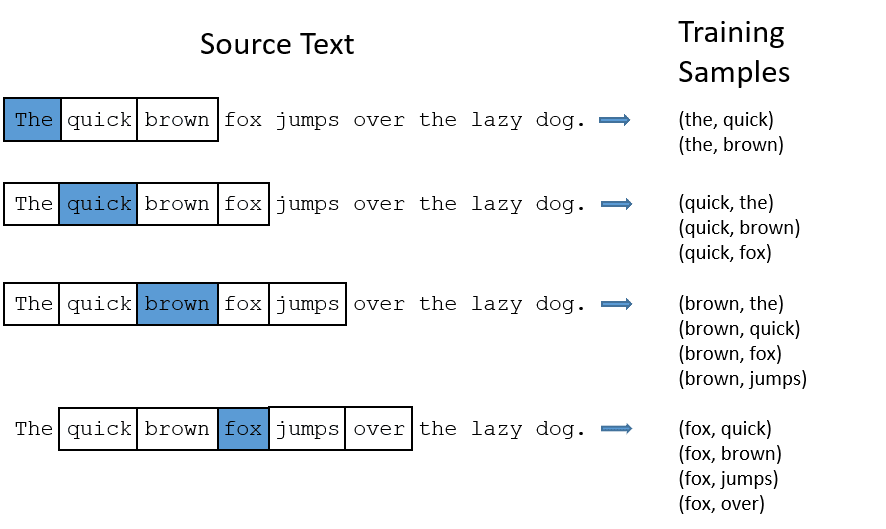
La rete alla fine dell'apprendimento di datà per una data paralo la probalibilità delle parole "VICINE" per una data FINESTRA di calcolo ad esempio se 5 saranno (5 prima e dopo = 10 parole)
La rete verrà allenata con coppie di parole che derivano dalla larghezza della finestra di analisi
ES: FINESTRA 2 (5 parole in tutto con quelle centrale)
La rete imparerà dalle statistiche del numero di volte che compare una data coppia
Prendiamo un vocabolario di 10000 parole
Una parola è rappresentata da un One-Hot Vettore
1,0,0,0,0,0, ..... 0 (10000 elementi) la prima parola del vocabolario
0,1,000000 .....0 la seconda ecc..
L'output della rete sarà SOFTMAX (valori fra 0-1) con la probailità che la parola sia "VICINA"
TRAINING: INPUT = one-hot vector OUTPUT one-hot vector
EVALUATING INPUT=one-hot vector OUTPUT softmax

HIDDEN LAYER
se vogliamo apprendere 300 features i neuroni saranno 10.000 x 300
300 parametro usato da Google per i suoi dataset ma è modificabile "Hyper Parameter"
Il fine è calcolare i pesi dell'HIDDEN LAYER
THE OUTPUT LAYER
il vettore one-shot di una parola produce sull'output un soft max classificatore
Ogni neurone output si moltiplica con il word vector dell'Hidden layer e si applica la funzione exp(x) la vlaore finale e si divide il tutto per il totale sui 10000 nodi

------------------------------------------------------------------------------------------------------------
Tf + BagOfWords
TensorFlow esercizi
| Evernote consente di ricordare tutto e di organizzarti senza sforzo. Scarica Evernote. |
Comments